The Umpires Just Love Him
Yes, it’s another useless Brownlow predictor.
Football fans often discuss how umpires love (or favour) certain players, particularly if the player receives a free kick the crowd doesn’t feel they deserve. But could this hypothetical favouritism extend to giving out Brownlow votes?
For this post I used a very scientific and technically correct formula to predict who will win the Brownlow based on votes awarded in previous games:
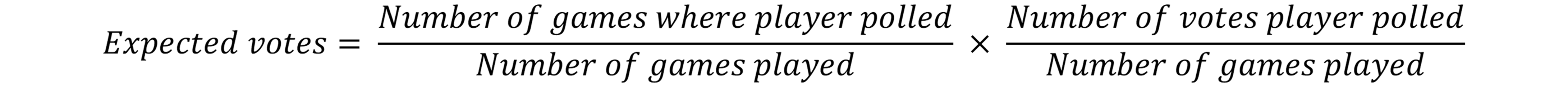
And then applied this to the number of games involving each umpire this year.
For example, Christian Petracca played 14 home and away games where Ray Chamberlain umpired prior to the 2023 season. He polled six votes across two of these games. So, the probability of Petracca polling in a Chamberlain-officiated game is 2/14 = 0.1429, for an average of 6/14 = 0.4286 votes per game. Multiplying the two gives us 0.061 expected votes per game.
We then multiply the expected votes per game by the number of games each player/umpire combination appeared in for the 2023 season to get the number of predicted votes. Petracca played in three games this year with Razor umpiring, so we would predict he will earn 3 x 0.061 = 0.183 votes from Razor. If you add up all these predicted votes for each player/umpire combo, you get the total number of votes for the year.
Based on this method, Lachie Neale will be a runaway winner this year, a whopping 10 votes clear of Christian Petracca. Bontempelli fills the last spot on the podium.
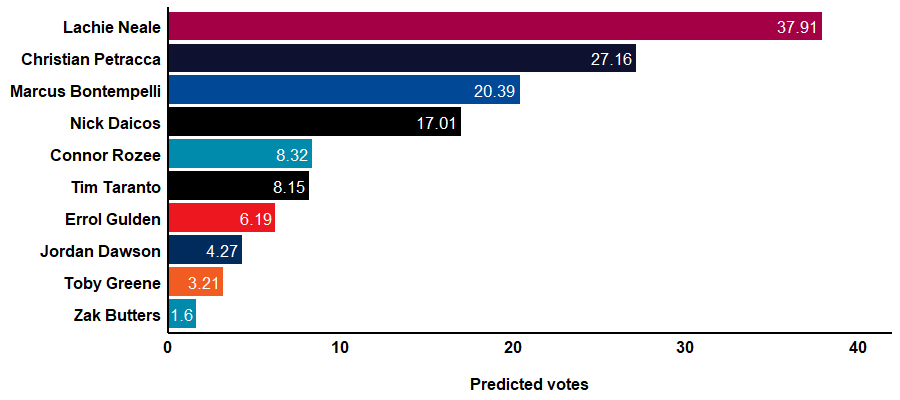
It goes without saying that this is meant to be a fun thought experiment, like yesterday’s post about predicting Brownlow votes based on the day of the games. I don’t think there’s any world where Neale wins by 10 votes and Butters polls single figures.
There are lots of limitations to the stats presented above. One key limitation is the umpires work as a team to assign the votes, rather than voting individually. Another limitation is that this approach favours players who have a history of polling votes and punishes those who haven’t polled as many votes in their career. Daicos seems to be an exception to the rule, predicted to poll 17 votes this year despite only polling 11 in his one previous season.
This is a great example of the famous quote from British statistician George Box:
“All models are wrong, some are useful.”
Except this model is more useless than useful.
The timeframe of this stat is limited based on what data are freely/easily available and/or accessible. Please don’t hesitate to contact me if you spot any errors in what I have presented. As always, apologies to anyone who has already looked at this stat.